Tesla A100发布: 英伟达GPU架构如何演进?
Tesla A100发布: 英伟达GPU架构如何演进?NVIDIA(英伟达)2020年度黑科技秀GTC 2020大会,近期通过在线视频的方式举办,发布了史上最强的GPU——NVID

NVIDIA(英伟达)2020年度黑科技秀GTC 2020大会,近期通过在线视频的方式举办,发布了史上最强的GPU——NVIDIA Tesla A100,全球最强AI和HPC服务器平台HGX A100、全球最先进的AI系统——DGX A100系统、Orin SoC系列自动驾驶芯片和全新DRIVE AGX平台。
Tesla A100震撼全球,NVIDIA A100在AI训练(16位单精度操作,FP16)和推理(8位整数操作,INT8)方面,GPU比VoltaGPU强大20倍。在高性能计算(双精度运算,FP32)方面,NVIDIA表示GPU的速度将提高2.5倍。
关于什么是INT8,INT8 指用8个位表示一个数字,FP32是指采用32位表示一个浮点数字,INT8精度低,一般用于推理,但也有些优势。
优势1:INT8能有效降低带宽,减少运算吞吐,提升计算能力,而精度损失低优势2:INT8的乘加运算无论芯片面积还是能耗都优于FP32,FP16等。
A100 作为NVIDIA的第一个弹性多实例GPU统一了数据分析,训练和推理;并将被世界顶级云提供商和服务器制造商采用。
其中阿里云、AWS、百度云、 谷歌云、微软Azure、 甲骨文 和腾讯云计划提供基于A100的云服务;Atos、Cisco、Dell、Fujitsu、GIGABYTE、H3C、 HPE、 Inspur、 Lenovo、 Quanta/QCT 和 Supermicro等系统制造商将基于A100推出服务器服务器。
A100借鉴了NVIDIA Ampere架构的设计突破,在八代GPU架构中提供了该公司迄今为止最大的性能飞跃,统一了AI培训和推理,并将性能提高了20倍。A100是通用的工作负载加速器,还用于数据分析,科学计算和云图形。

Ampere GA100是迄今为止设计的最大的7nm GPU。GPU完全针对HPC市场而设计,具有科学研究,人工智能,深度神经网络和AI推理等应用程序。NVIDIA A100 是一项技术设计突破,在五项关键技术领域得到创新和突破:
NVIDIA Ampere架构 — A100的核心是NVIDIA Ampere GPU架构,其中包含超过540亿个晶体管,使其成为世界上最大的7纳米处理器。基于TF32的第三代张量核(Tensor Core): Tensor核心的应用使得GPU更加灵活,更快,更易于使用。TF32包括针对AI的扩展,无需进行任何代码更改即可使FP32精度的AI性能提高20倍。此外, TensorCore 现在支持FP64,相比上一代,HPC应用程序可提供多达2.5倍的计算量。多实例(Multi-Instance)GPU — MIG是一项新技术功能,可将单个A100GPU划分为多达七个独立的GPU,因此它可以为不同大小的作业提供不同程度的计算,从而提供最佳利用率。第三代NVIDIA NVlink —使GPU之间的高速连接速度加倍,可在服务器中提供有效的性能扩展。结构稀疏性—这项新的效率技术利用了AI数学固有的稀疏特性来使性能提高一倍。
MIG是一种GPU划分机制,允许将一个A100划分为多达7个虚拟GPU,每个虚拟GPU都有自己专用的SM,L2缓存和内存控制器。与CPU分区和虚拟化一样,此系统背后的思想是为在每个分区中运行的用户/任务提供专用资源和可预测的性能水平。
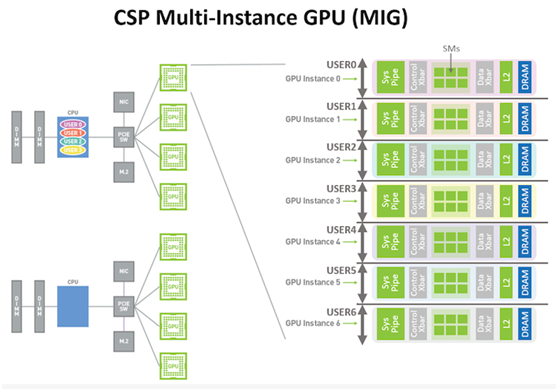
MIG遵循了NVIDIA在该领域的早期工作,为虚拟图形需求(例如GRID)提供了类似的分区,但是Volta没有用于计算的分区机制。结果,虽然Volta可以在单独的SM上运行来自多个用户的作业,但它不能保证资源访问或阻止作业占用大部分L2缓存或内存带宽。相比之下,MIG为每个分区提供了专用的L2缓存和内存,从而使GPU的每个部分都完全完整而又完全隔离。
3 首页 下一页 上一页 尾页-
超奔驰宝马!雷克萨斯进口车销量中国第一2020-05-19
-
全球近100家苹果店已重新开放,给顾客提供口罩2020-05-18
-
华为再次立功!国产自动驾驶操作系统首获国际认证2020-05-18
-
专注工业无人机全自动飞行系统解决方案,“复亚智能”获数千万元A轮融资2020-05-18
-
小学生已泪奔!腾讯游戏防沉迷系统再迎升级:上线人脸识别2020-05-15
-
临床研究一体化解决方案提供商铨融医药科技完成数千万元A+轮融资2020-05-15
-
郭明錤透露苹果革命新新品VR眼镜:搭载特定iOS系统!2020-05-15
-
研发无人机自动巡逻巡检系统,复亚智能完成数千万元人民币A轮融资2020-05-15
-
哈曼卡顿推出CITATION音乐魔力5.1家庭影院系统2020-05-15
-
和信康舌诊AI系统首获中医科学院认证,促进中医传承创新发展2020-05-15
-
和信康舌诊AI系统首获中医科学院认证,促进中医传承创新发展!2020-05-15
-
焕一生物| 人工智能赋能系统免疫学,开启精准诊疗新时代2020-05-14
-
用SPHRINT为新型药物输送系统打印3D微观结构2020-05-14
-
微软将停止支持32位Win10系统,32位系统将慢慢退出舞台2020-05-14
-
兰茜生物:推出“AI病理医生”辅助诊断系统2020-05-14