Google发布大规模实例级检索和识别基准数据集GLDv2
Google发布大规模实例级检索和识别基准数据集GLDv2随着图像检索和实例识别技术的迅速发展,急需有效的基准数据来对不断出现算法的性能进行有效测评。来自谷歌的研究人员为此设计并推
随着图像检索和实例识别技术的迅速发展,急需有效的基准数据来对不断出现算法的性能进行有效测评。来自谷歌的研究人员为此设计并推出了Google Landmarks Dataset v2(GLDv2)数据集用于大规模、细粒度的地标实例识别和图像检索人物。这一数据集包含了200k个不同实例标签共5M张图像,其中包括测试集为检索人物标注的118k张图像。
这一数据集的特点不仅在于规模,而且在于考虑了许多真实应用中会遇到的问题,包括长尾特性、域外图像、类内丰富多样性等特点。这一数据集除了可以作为检索和识别人物的有效基准外,研究人员还通过学习图像嵌入呈现了其用于迁移学习的潜力。
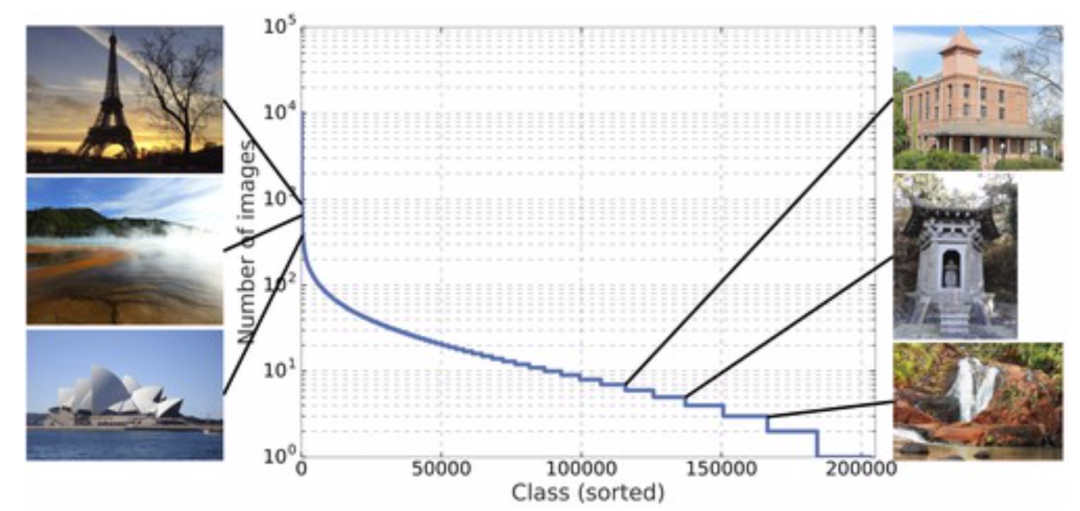
图像检索与实例识别
图像检索和实例识别是计算机视觉研究领域的基本课题已经有很长的研究历史。其中图像检索的目的是基于查询图像来排序出最为相关的图像,而实例识别则是为了识别出目标类别中的特定实例(例如从“油画”类别中识别出“蒙娜丽莎”实例)。
但随着技术的发展,两种任务开始结合提高了技术额鲁棒性和规模性,早期的数据集越来越不足以支撑算法的发展。此外在图像分类、目标检测等领域都出现了像ImageNet、COCO、OpenImages等大规模的数据集,而图像检索领域还在使用Oxford5k和Paris6k等数据较少、时间较老的数据集。由于其大多只包含了单个城市的数据,使其训练的结果难以大规模的泛化。
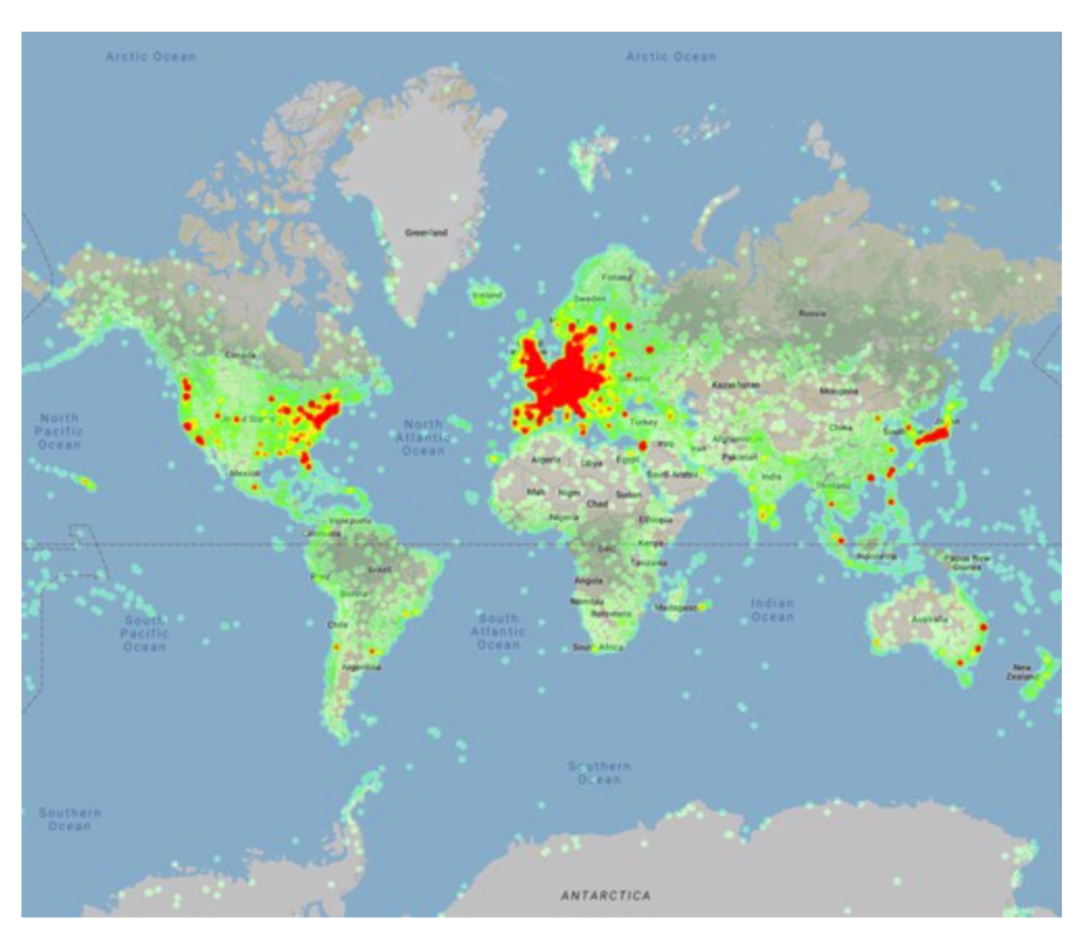
世界范围内的数据采集点的分布
很多现有的数据集都没有涵盖真实条件下的挑战。例如用于视觉检索的地标识别app会收到大量非地标的查询图像,包括动植物或各类产品等,这些查询图像原则上不应该得到任何查询结果。此外绝大多数实例识别数据集仅仅有专题查询能力,同时无法测量域外数据的假阳性率。
研究人员迫切需要更大、更具挑战的数据来测评技术的发展,同时为将来的研究提供足够的挑战和动力。这一领域缺乏大规模数据的原因在于上千个标签和上百万图像中进行数千个标签的细粒度标注十分耗费人力,同时也不是简单的外包可以完成,需要专业知识才能有效标注。为了解决这些问题,新的数据呼之欲出!
GLDv2
这一新数据集的主要目的是为了尽可能的模拟和覆盖真实工业场景地标识别系统所面临的挑战。为了尽可能地覆盖真实世界,需要非常多的图像,因此这一数据集首先需要满足大规模的特性;其次为了适应多种光照条件和视角,还需要每一个类别或实例标签中的图像具有丰富的类内多样性。真实情况下绝大多数图像来源于著名的地标,而还有很多来源于不那么知名的地点,所以数据集还需要具备长尾特性。最后一个问题,在实际使用中,用户会上传各种各样的查询图像,只有非常少的一部分图像存在于数据集中,那么这些数据需要满足域外查找特性(即能够在不包含在训练集中的查询图像上依然有效运行)。这些实际情况中的特点为识别算法的鲁棒性提出了非常大的要求。
在这些因素的指导下,研究人员们开始收集对应的图像并进行标注。数据主要来源于Wikimedia Commons,这是Wikipedia背后支撑的媒体资源库。它覆盖了世界范围内大部分的地标,同时还包括了Wiki Loves Monuments来自世界各地的文化遗迹高质量细粒度照片。此外研究人员还从众包中获取了真实的查询照片。
在获取了图像后就需要标记数据集建立索引了。下图显示了从Wikimedia Commons中挖掘地标图像的流程。

Wikimedia Commons中是按照分类学的方式组织资源。每一个分类有独特的URL其中包含了所有相关的图像列表。但这种方式并没有合适的顶级分类来映射人造和自然地标的,于是研究人员采用了谷歌知识图谱来发掘世界范围内的地标。
为了获取WikiCommons中与地标相关的分类,研究人员从谷歌知识图谱中查询了“landmarks”,“tourist attractions”,“points of interest”等等词条,每次查询都会返回图谱实体,利用这一实体来获取Wikipedia中的文章,并跟随文章中的链接找到Wikimedia Commons分类页面。随后将所有图像下载下来,并利用严格的分类来确定每一张图像对应一种分类,并利用Wikimedia Commons中的url作为典型的类别标签。依照这样的方式获取了训练和索引集。而查询数据集的构建则包含了包含地标的positive查询和不包含地标的negative查询。
由于视觉上的检查发现检索和识别结果出现了一些错误,主要由于遗漏了基准标注,原因源于以下几个方面:众包带来的错误和遗漏、某些查询图像包含多个地标,但基准只有一个结果、某一图像在不同层次具有不同的标签、某些negative查询图像实际上是地标图像。为了解决这些问题,需要对测试集进行重新标注。

GLDv2数据集与其他数据的比较
最终研究人员得到了五百万张超过二十万个不同实例地点的数据集,成为了目前领域内最大的实例识别数据。它最终分为三个部分,一部分是118k包含基准标注的查询数据、4.1M图像包含203k地标标签的训练数据、包含101k地标的762k张索引图像。此外还给出了一个小型的数据集包括1.2M图像和15k地标。与其他数据集相比,这一新数据集的规模和多样性都是无可比拟的:


采集自世界范围内的图像,分类图显示了超过25k地点类别直方图
强有力的数据集
为了检验这一数据集的能力,研究人员进行了一系列实验。首先在GLDv2数据上进行训练,测试了模型的迁移能力。通过学习全局描述子并测评他们在独立地标检索数据中的表现(Revisited Oxford,ROxf 和 Revisited Paris, RPar) 。下表显示了这一数据集可以显著提高模型的性能,mAP的提升将近5%。
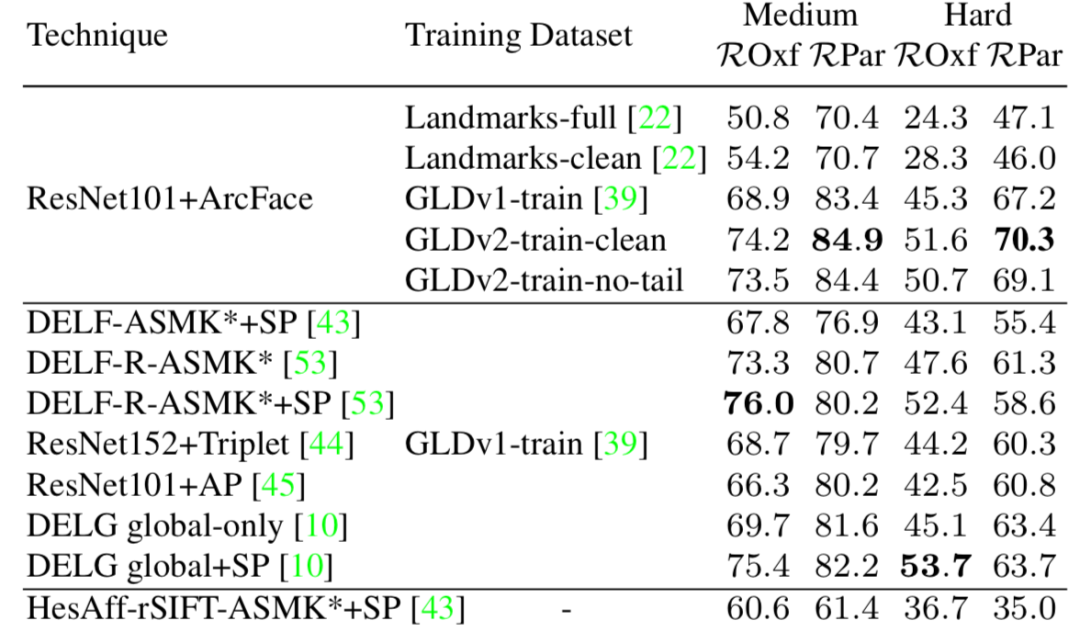
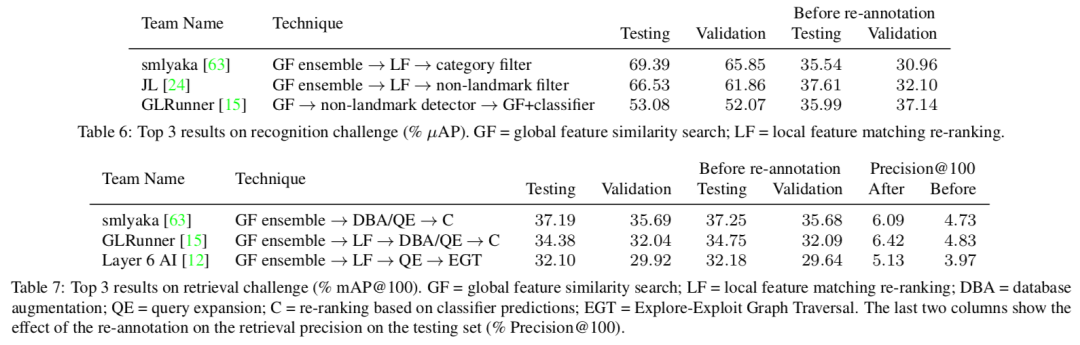
针对识别和检索任务下面两个表展示了基于不同模型和数据集上的比较结果可以看到基于GLDv2数据集的模型性能得到了显著提升。
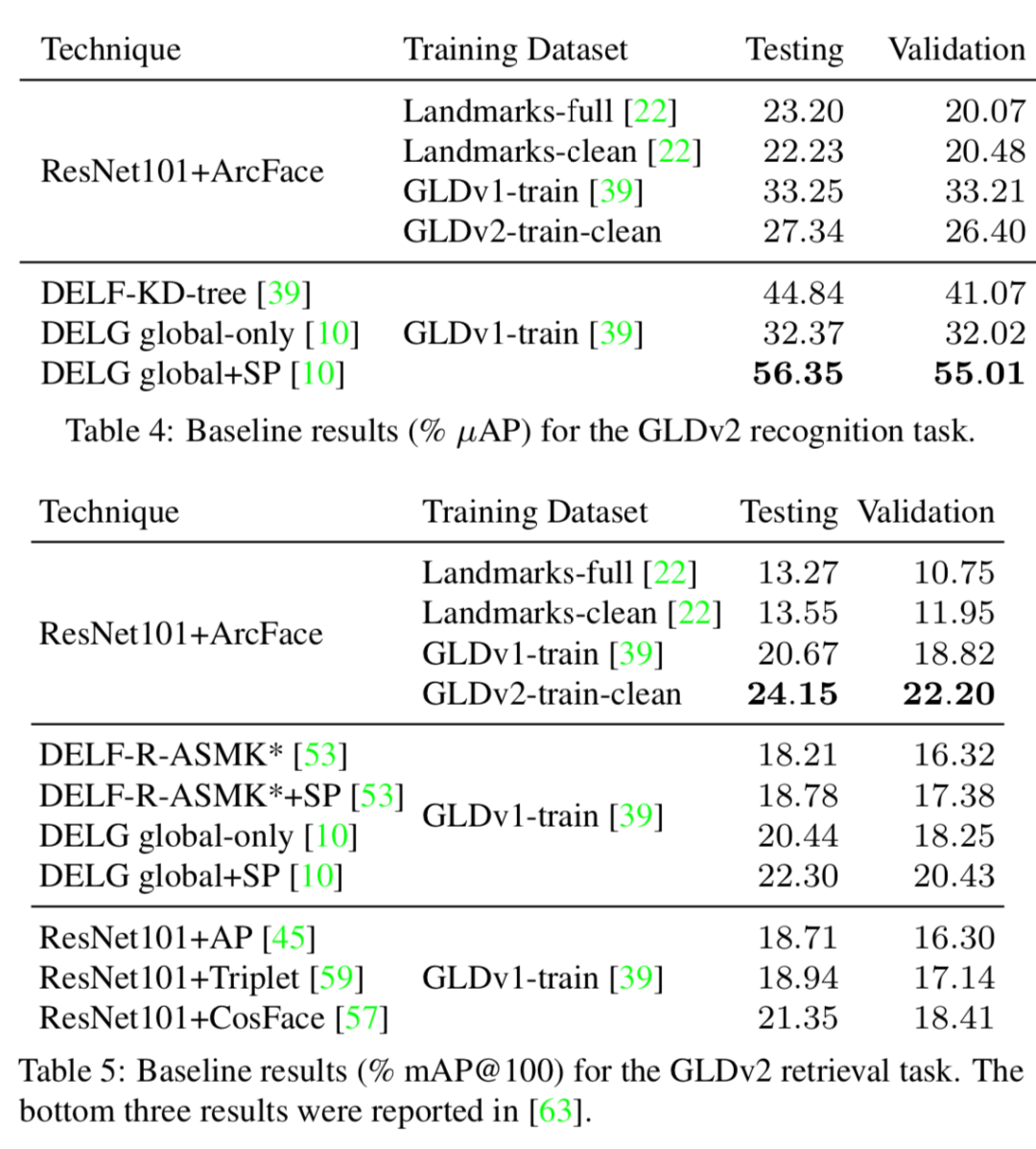
此外在检索挑战任务上进行了测评,包括了全局特征搜索和局域特征匹配重排等技术。结果显示,即使使用了复杂的技术,这一数据集仍然具有可以挖掘提升的空间。
上一篇:你的智能汽车能否聪明的绕开物体?
-
新基建时代,数据中心将迎来AI赋能下的进化浪潮2020-04-16
-
扫地机器人哪款好?大数据分析扫地机器人十大品牌排名2020-04-15
-
爱生生命科技:调研数万高龄老人肠道菌群生态,AI结合大数据预估健康风险助力长寿2020-04-15
-
回收宝公布荣耀VS红米手机保值数据,雷军投资回收宝再添“实锤”2020-04-15
-
2月没卖出一辆车的力帆,这一次又上演了“兄弟相残”2020-04-15
-
定位上海,AutoX建立首个自动驾驶“超级数据工厂”2020-04-15
-
首发丨定位上海,AutoX建立首个自动驾驶“超级数据工厂”2020-04-15
-
广西“五网”新基建正式启动 一天开工两个数据中心2020-04-15
-
总投资3.3亿元!河南又一大数据中心项目落地2020-04-15
-
数据存在局限性:瑞德西韦中国重症临床试验已中止!2020-04-12
-
数据科学平台,Cool!但并不孤独2020-04-10
-
搭乘新基建的东风,工业互联网如何抓住这一发展机遇?2020-04-09
-
抗击疫情!武汉大学提出口罩人脸识别数据集和模型, 95%精度不在话下2020-04-09
-
腾讯造出中国第一台临床应用智能显微镜:视野中直接显示数据2020-04-09
-
康奈尔大学研究员提出利用归一化信息, 提取图像特征中结构性信息的新方法2020-04-09