图形学+深度学习:来看下神经渲染完成的神仙操作!
图形学+深度学习:来看下神经渲染完成的神仙操作!现代计算机图形学在合成逼真场景图像和场景操控合成方面取得了杰出成果,然而在自动生成形状、材质、光照和其他场景方面还面临着一系列挑战。
现代计算机图形学在合成逼真场景图像和场景操控合成方面取得了杰出成果,然而在自动生成形状、材质、光照和其他场景方面还面临着一系列挑战。而计算机视觉与机器学习为这一领域提供了图像合成与编辑的全新解决方案:基于深度生成模型和图形学领域的光学物理知识,神经渲染(Neural rendering )已成为计算机图形学领域最为迅猛的发展方向。在多种计算理论、方法和技术的融合下,这个新领域出现了非常多的有趣应用:包括图像内容编辑、场景合成、视角变化、人物编辑等等。可以预见,神经渲染未来将会在电影工业、虚拟/增强现实和智慧城市等领域中发挥越来越重要的作用。
来自马普研究所、斯坦福、慕尼黑理工、Facebook、Adobe和谷歌的研究人员对这一领域的发展进行了详尽的综述,系统性地梳理神经渲染在各个领域的发展。下面我们将为大家详细呈现机器学习、计算机视觉与图像学领域的碰撞融合。
语义图像合成与操控
语义图像合成与操控主要利用交互式的编辑工具来对图像中的场景和物体进行语义上地控制和修饰。与传统方式不同,数据驱动的图形学系统可以利用多张图像区域来合成新的图像,并基于大规模的图像数据集来抽取典型的语义特征。这种方法可以使用户指定场景的结构、修改场景内容,同时还能有效处理合成过程中产生的不连续性和人工痕迹。
在语义图像合成方面,目前主要基于条件生成目标,将用户指定的语义图映射为逼真的图像。用户输入还包括了颜色、草图、纹理等形式。从pix2pix等方法开始,研究人员们就开始对场景和图像的生成进行深入的探索,并不断提高生成图像的分辨率与细节,同时从静态图像向动态视频的语义操控扩展。下图显示了目前较为先进的GauGAN网络生成的结果:其不仅可以生成较好的视觉效果,还能控制生成结果的风格和语义结构。

在语义图像操控方面,该技术需要用户提供待操作的图像,并利用生成模型满足用户对图像的操作需求。与前述的合成不同,操作面临两个额外挑战:其一,对图像的操作需要对输入进行精确的重建,但这对于目前最为先进的GAN来说也是挑战;其二,操作图像后合成的结果也许会与输入的图像不兼容、不协调。
于是为解决这些问题,研究人员们提出了非条件GAN来作为神经图像先验,同时通过生成结果与原始图像的融合来得到输出结果。此外,包括自动编码器等多种内部结果的使用和后处理的有效应用也使得图像编辑取得了良好的效果。下图显示了GANPaint中如何给图像增加、删除、改变目标:只需用笔刷进行涂抹,生成模型就会满足用户提出的需求,同时保留原图像中的统计信息。

在提升渲染图像的真实性方面,研究人员从大规模的真实数据中抽取相似的内容来提升渲染图像的结果,或者基于条件生成模型,将低质量的渲染结果转换为高质量的逼真图像。此外,包括特征匹配,阴影处理、材质和表面法向量渲染等方面的工作也将对全局光照、遮挡、景深和连续性进行处理。下图显示了基于生成模型的高质量渲染结果:仅仅改变视频中说话人的嘴形,就渲染出了近乎真实讲话的视觉效果。

目标和场景的新视角合成
新视角合成是指在特定场景下,利用已有的不同视角图像,在新相机视角条件下合成图像。其最主要挑战来自于场景的三维结构观测比较稀疏,需要在仅有的几个观测视角下合成出新视角的图像,同时还需要补全新视角下被遮挡或者没有在观测中被包含的部分。
在经典计算机视觉中,人们主要基于多视角立体视觉来实现场景几何重建,用反射变换来构建基于图像的渲染效果。但在稀疏观测或者欠观测的情况下,这种方法得到的结果会具有孔洞,或是留下较为明显的人工凿斧痕迹。在神经渲染中,研究人员使用少量的已有视角观测结果来学习出场景,再利用可差分的渲染器生成新视角下的图像;同时还利用几何、外观与场景特性作为先验来提升场景的表达和渲染;此外还通过体素、纹理、点云等多种形式来为网络提供更多的图像和几何信息。
下图显示了神经渲染从大规模网络图像中重建3D模型的结果。模型被渲染为了深度、颜色和语义标签等缓存中,渲染器将这些缓存转换为了多种不同的场景结果。

下图展示了从新视角渲染招财猫的图像结果。由图可见,在仅仅六个稀疏采样视角下,系统就实现了多个新视角的目标渲染。

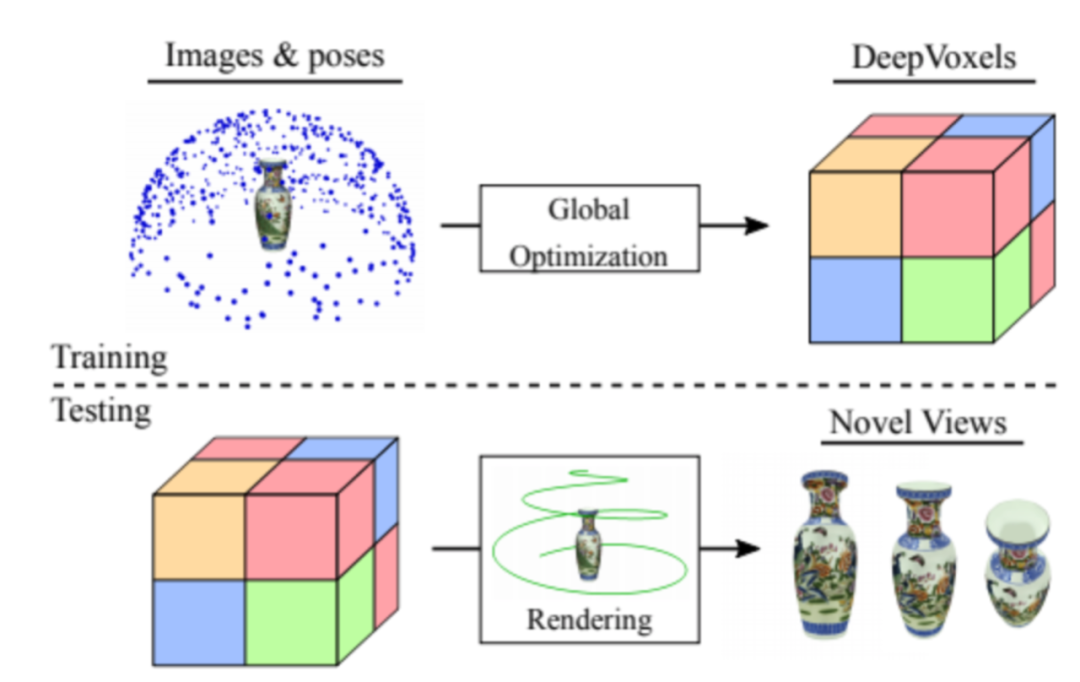
神经渲染在学习场景中自然的三维结果和透视几何关系方面也发挥了重要作用,下图显示了几个具有代表性的新视角合成工作:

-
新基建加速服务机器人行业,猎户星空如何开拓医疗场景2020-04-15
-
易诚高科作为唯一一家5G场景仿真企业,入选腾讯5G生态计划2020-04-10
-
康奈尔大学研究员提出利用归一化信息, 提取图像特征中结构性信息的新方法2020-04-09
-
AI应用场景广阔 如何兼顾安全与发展2020-04-08
-
腾讯自动驾驶落地路径:率先满足高频场景 充分发挥OTA价值2020-04-08
-
室外场景应用崛起,清洁机器人迎来新机遇2020-04-08
-
“PharmCoo”落地多场景应用,京东健康携北医三院共担AI创新重大课题2020-04-08
-
腾讯5G生态计划落地12个5G场景,首批45个行业应用接入2020-04-08
-
下一代三星Galaxy Buds渲染图曝光:蚕豆外形2020-04-05
-
5G CPE:一场即将打响的场景革命2020-04-02
-
等待爆发的远程医疗等场景,5G CPE会是幕后推手吗?2020-04-02
-
布局C端B端全场景,优必选将打造怎样的机器人帝国丨亿欧解案例2020-04-01
-
开发者的小宇宙,与华为全栈全场景AI同频扩张2020-03-29
-
AI全栈全场景开发已就绪 华为Atlas激发无限可能2020-03-29
-
华为全场景AI计算框架MindSpore正式开源,赋能开发者昇腾万里2020-03-28