网络电话质量差,WaveNetEQ来帮忙
网络电话质量差,WaveNetEQ来帮忙网络电话对于人们日常的工作生活具有不可或缺的重要作用,从微信到钉钉再到国内外各种各样具有语音功能的App都在便捷着我们的生活。为了通过网络将

网络电话对于人们日常的工作生活具有不可或缺的重要作用,从微信到钉钉再到国内外各种各样具有语音功能的App都在便捷着我们的生活。为了通过网络将电话传输到另一端,语音电话的数据会被分为一个个数据包来进行传输,而后在接收端重组为连续的音视频数据流。

然而数据包在传输到接收端的时候会存在乱序和丢包的情况,从而造成通话的抖动。由于接收端尝试对丢包的区域进行补偿会造成通话质量的大幅下降。这一问题广泛存在于各种音视频传输过程中,据统计在谷歌Duo应用中大约有99%的通话需要处理丢包、过多的抖动和网络延迟;而这些通话中,20%的部分由于网络问题损失了超过相当于整体3%的时长、10%的部分则损失超过了8%。
下图显示了网络问题造成的丢包,需要接收端对抗丢包乱序来实现可靠的实时通信。
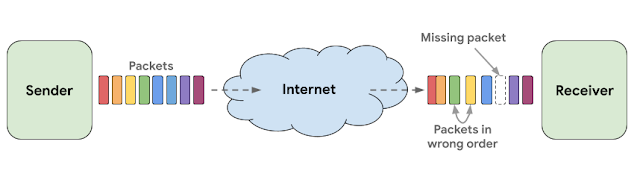
有效解决丢包和乱序问题是可靠实时通信的保证。特别是当音频不是连续时用户就会听到通话中的瑕疵和间隔,但为了可靠通信多次重复语音显然不是理想的办法,既降低了整体质量又产生明显的人工痕迹。学术界将处理丢包的过程称为包丢失修复(packet loss concealment ,PLC)。接收器的PLC模块负责创建音视频数据来填充由丢包、过分抖动或者网络故障造成的空隙。
为了有效解决通话过程中的数据丢失问题,研究人员提出了一种新型的PLC系统WaveNetEQ。这是一种基于WaveRNN技术的生成模型,由大量真实的短语音片段构成的语音数据语料库进行训练,来完整地合成丢失数据的原始语音波形。由于Duo是端到端加密的通话系统,所有的处理需要在设备端进行。研究人员优化WaveNetEQ可以在手机上高效运行,同时提供了最为先进的通话质量和更为自然的PLC结果。
用于Duo的PLC新系统
Duo和许多基于Web的通信系统一样都是基于WebRTC开源项目而构建的。为了消除丢包的影响,WebRTC的NetEQ模块采用了信号处理的手段,通过分析语音来得到平滑连续的声音结果。这种方法在20ms以内的丢包时表现较好,但却无法有效处理超过60ms的丢包结果。丢包较多会造成语音变成机器人风格或者不断重复,相信你在打网络电话时一定遇到过这样的情况。
为了更好的处理丢包现象,研究人员将NetEQ PLC部分替换为了经过改造的WaveRNN。这种用于语音合成的递归神经网络包含两个主要部分,自回归网络和条件网络。自回归网络主要负责信号的连续性并生成中短期的语音结构,生成样本基于网络先前的输出。而条件网络则会影响自回归网络来生成包含更多输入缓变特征的音频结果。
然而WaveRNN和WaveNet等都是文本语音合成模型,任务为其提供了需要表达和如何表达语音的信息。条件网络直接以音素的形式接收信息用于弥补词语和额外的韵律特征(包括像语调和音高等所有非文本特征)。这样的处理方式下,条件网络可以预见未来的趋势并协助自回归网络来生成正确的波形以匹配这些特征。但在PLC和实时通信系统中,缺乏这样的上下文信息。
针对一个实用的PLC系统来说,既需要从当前和过去的语音中抽取上下文信息,同时需要生成有效的声音来延续语音序列。在WaveNetEQ中这两项任务同时进行,利用自回归网络在包丢失的情况下提供音频连续性,条件网络则为声音特点等长程特征进行建模。先前音频信号的声谱作为条件网络的输入,并作为条件限制了韵律和文本内容的上下文信息。经过压缩的信息随后被送入自回归网络,并结合最近的音频特征来预测下一个样本的波形结果。
但在WaveNetEQ模型的训练中有些许不同,自回归器的接收实际上是从当前的训练数据中采样得到用于下一步骤的计算的,而不是利用其输出的上一个样本。这一过程称为teacher forcing的强制约束,以保证模型学习到有效的信息,即使是在预测质量较低的训练开始阶段也是如此。一旦模型被充分训练并应用于音视频通话上,teacher forcing仅仅被用于在第一个样本时为模型热身,随后其输出被传输模型进行下一步预测。

WaveNetEQ的架构,在推理时利用teacher forcing来为自回归编码器热身。随后利用自身输出作为模型下一步预测的输入。长程音频部分的梅尔谱则作为条件网络的输入。
这一模型被应用于Duo中的语音抖动缓存器中。当在丢包发生后生成了模型延续了音频,研究人人员就将合成音频流与真实音频流进行融合。为了得到匹配更好的融合信号,模型生成了稍微多一点语音信号,随后利用交叉渐变的方法进行相互融合,得到噪声更少转变更为平滑的结果。
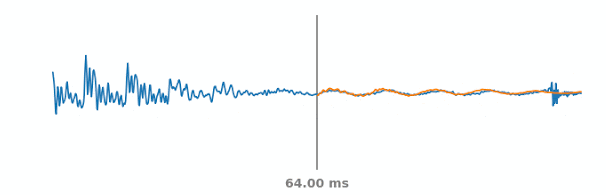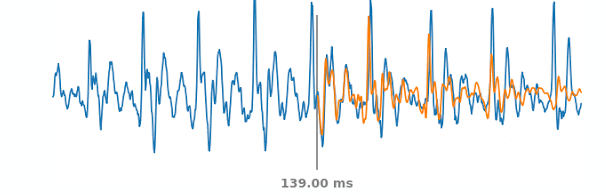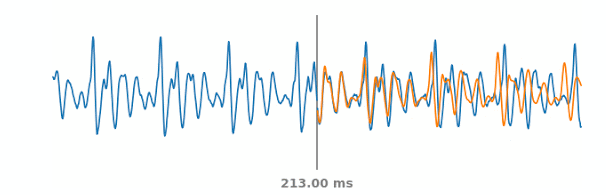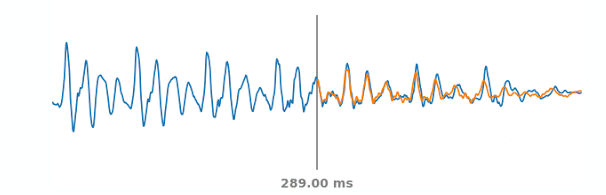
上图显示了模拟的PLC情况。蓝色线代表了真实的音频信号,包括PLC事件过去和将来的部分。在每一个时间步长下如果灰线处音频发生突变,WaveNetEQ将预测出橙色线代表的合成音频。
鲁棒性
PLC过程中一个重要的因素是模型具有适应变换输入的能力,包括不同的说话人或者背景噪声的变化。为了保证模型在不同用户间的鲁棒性,研究人员利用来自于超过100个用户和48中不同语言的数据对WaveNetEQ进行了训练。为了保证WaveNetEQ可以处理不同的噪声环境,包括车站或者咖啡馆等等,训练数据还利用不同的背景噪声混合进行了增强。
虽然这一模型可以有效地衔接语音,但它只在小尺度上表现良好。它可以有效处理音节,但是还无法有效处理词句。随着时间的延长,在120ms后模型就无法预测出有效的结果。为了保证模型不生成错误的音节,研究人员利用谷歌云语音转文字API测评了从WaveNetEQ和NetEQ中采集的样本,实验没有发现词错误率明显差别(语音转文字的错误率相当,意味着这种方法没有造成更多的错误音频)。
目前WaveNetEQ已经被用于Pixels 4的Duo上,对于提升通话质量和用户体验都起到了积极的作用,研究人员和相关团队也在继续开发更好的模型。
-
调查显示:消费者对5G和蜂窝网络质量很不满意2020-04-09
-
仙知小课堂丨仙知网络协议API使用教程(十五)2020-04-08
-
妈咪知道深圳儿科诊所业务接入企鹅杏仁,企鹅杏仁“城市模型”战略步伐加快2020-04-08
-
为提升siri性能,苹果收购语音AI初创公司Voysis2020-04-07
-
金融数据中心网络自动驾驶时代已来,助力数字化转型深化加速2020-04-07
-
火箭进入2500Mbps网络时代 Rivet发布Killer E3100网卡2020-04-04
-
物联网部署为什么需要低功率广域网络(LPWAN)?2020-04-03
-
封锁之下 两条海缆先后故障 南非网络连接受影响2020-04-03
-
物联网部署为什么需要低功率广域网络?2020-04-03
-
深度分析:AI和Wi-Fi 6推动家庭网络革命2020-04-03
-
Oro深度分析:AI和Wi-Fi 6推动家庭网络革命2020-04-03
-
新冠病毒大流行推动智能家居语音控制设备快速增长2020-04-02
-
“黑科技”来了!北京地铁进入魔幻时代:魔窗系统走红网络2020-04-02
-
高质量发展 高品质交付:中国信科助力运营商构建5G SA精品网络2020-04-02
-
网络建设提速 年底5G基站超60万个2020-04-01