深兰科学院基础研究厚积薄发,“长序列比对算法”助攻战“疫”
深兰科学院基础研究厚积薄发,“长序列比对算法”助攻战“疫”重磅新闻深兰科学院近日开发成功了一套独特的AI算法,将病毒基因全序列对比的时间缩减到3分钟,而蛋白序列的对比时间更是缩减到
重磅新闻
深兰科学院近日开发成功了一套独特的AI算法,将病毒基因全序列对比的时间缩减到3分钟,而蛋白序列的对比时间更是缩减到秒级。利用此独特的AI算法和非线性动力学混沌可视化理论,可进一步研究新型冠状病毒的蛋白靶标,尽快找到新型冠状病毒的药物筛选。
比如SARS和新冠病毒(2019-nCov)的S蛋白对比只需3秒钟,结论是两者S蛋白的氨基酸序列的相似度为71.88%,最长相同序列分别位于两者的926和944位点,长度为111。这项科研成果的意义在于基因和病毒学家可以据此进行广泛的基因对比,从而确定病毒的族谱关系和进化路径,为后续疫苗和药物研发提供依据。
目前深兰科技决定向全社会开放这项功能,任何科学工作者只要向深兰申请,即可根据所提供病毒基因序列或者序列片段,快速获得对比结果、族谱关系图和深兰独创的“病毒序列的功能性对比”。
近日深兰科学院深度学习科学家方林博士在比对武汉新冠病毒与其他病毒(比如SARS)基因片段时,便利用了计算机科学中的next 值概念和相关算法大大提高了长序列对比的速度。
用普通方法,长序列比对的时间复杂度是:

这使得长序列比对十分耗时。而长序列比对在科研工作中用途十分广泛,比如基因测序中的一个重要工作就是对两个基因序列或者序列片段进行比对,得出两者之间哪些部分相同,哪些部分不同的结论。
下文将以科普的性质介绍什么是序列比对、序列比对中的难题,以及next值概念,其中更多地是向大家介绍分析问题和解决问题的一般方法。不管你是不是技术和科研人员,不管你是不是计算机专业,希望本文都能对你有所启迪。
长序列比对算法研究
深兰科学院 方林博士
1、什么是长序列比对
给定两个序列,所谓比对就是告诉我们这两个序列哪些部分是相同的,哪些是不同的。比如字符串ABCACAABBC和BCBAABBA,他们的比对结果如下所示:

其中,中括号扩起来的部分就是两个字符串的相同部分。通过上下对应,我们可以很清楚地看到两个序列中哪些部分相同,哪些部分不同。
在下面的叙述中,我们都用字符串作为序列来说明。对于其他类型的序列,比如整数序列,我们的结论和方法同样成立。
2、长序列对比要解决的问题
2.1 耗时
首先,长序列对比很耗时。如果采用普通方法,第一个字符串的每一个可能子串都要与第二个字符串的任意一个长度相同的子串对比。假设两个字符串的长度都是n(当然,实际比对时两个字符串的长度不一定相同,这里只是为了简化我们的讨论而假设它们长度相同),我们可以计算一下要进行多少次比较。
两个字符串中,长度为1的子串各有n个,于是要进行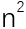 次字符比较。
次字符比较。
长度为2的子串各有n-1个,于是要进行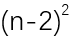 次匹配,平均每次匹配要进行1次字符比较。
次匹配,平均每次匹配要进行1次字符比较。
……
长度为n的子串各有1个,要进行1次匹配,平均每次匹配要进行n/2次字符比较。
所以我们总共要进行12 + 22 + …… + 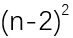 +
+ 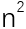 ,也就是n(n+1)(2n+1)/6次匹配。在计算机科学中,这种耗时的“复杂度”是
,也就是n(n+1)(2n+1)/6次匹配。在计算机科学中,这种耗时的“复杂度”是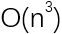 。也就是说,耗时跟字符串长度n的立方在一个数量级。更值得一提的是,如果我们把字符比较也考虑在内,则时间复杂度达到
。也就是说,耗时跟字符串长度n的立方在一个数量级。更值得一提的是,如果我们把字符比较也考虑在内,则时间复杂度达到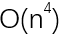 。
。
这意味着什么呢?这意味着如果长度增加2倍,则耗时增加16倍;如果长度增加10倍,则耗时就会增加10,000倍!
这是一个很可怕的数据。我用我的苹果Mac Air笔记本电脑做了一下测试。先拿两个长度为10的字符串测试,耗时6.69毫秒。可谓神速。然后用两个长度为100的字符串测试,耗时0.526秒。这个速度也还不错。等到我们用两个长度为1,000的字符串测试时,足足等了半个多小时也没有出来结果。为什么这样?因为理论计算需要耗时5,000多秒,足足1个小时20多分钟!
当然,你可以用计算服务器甚至超级计算机测试,结果肯定要好很多。但是一来,这样的计算资源很昂贵;二来,这并没有解决根本问题。比如,采用传统算法用计算服务器全序列比对两个病毒基因,耗时仍以小时计。
2.2 算法复杂
由于我们需要进行全序列对比,所以,并不是找到一个相匹配的字符串就完事了。
比如字符串AABABA和AACAABA,两个字符串的头两个字符都是AA。那我们就让这两个字符匹配然后只比较剩余的部分行不行呢?不行!因为第二个字符串后面还有子串AABA可以跟第一个字符串的头4个字符匹配,说不定后一种匹配更满足用户的需求呢?在对比两个长度很长的字符串(比如基因序列)时,这种情况比比皆是。
那么怎么解决这样的问题呢?计算机科学里有一个称为“回溯”的方法。这个“溯”字表明这个方法跟河流有关。的确,当我们解决算法问题时,就像沿着河流从上游往下游走,遇到河流分岔,意味着有多个方案供我们选择。所谓回溯,就是我们先沿着第一个分岔往前走,如果这个分岔后来走得通那就没什么好说的;如果走不通我们就回到分岔点,沿着第二个分岔往下走,……。以此类推,这样不就行了吗?
看起来好像是这么回事,但实际上并非如此简单。分岔的下游可能还有分岔,分岔的分岔还有分岔,……。所以我们要在每一个分岔点做好记录,以便如果将来从下游回溯到这一点时我们知道下一步该往哪个分岔走。只有把所有可能的分岔都走到,我们才有可能得到最优解。见下图:
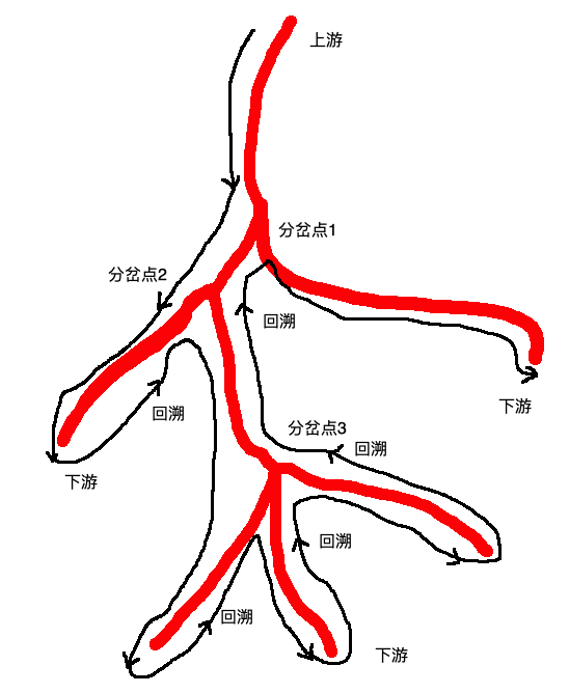
图中红色代表一条拥有众多分岔点的河流,黑色代表我们所走过的路。
比如,就拿上面提到的那两个字符串AABABA和AACAABA来说,我们可以先试着用AA匹配AA,最后看看这样匹配的结果是什么。比如说这样匹配的得分是100分,那么接着我们再考虑用AABA匹配AABA,假设得分是120,那么我们最终就采用后一个方案。
即使不考虑如何记录回溯点以及如何在回溯点恢复现场这样复杂的技术问题,回溯法仍然不是我们的最优选择。因为回溯并没有解决耗时问题,而只是解决了怎么做的问题。也就是说,虽然我们知道至少要进行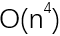 数量级的比较,但是怎么比较我们不清楚。而回溯就是回答这个问题的。
数量级的比较,但是怎么比较我们不清楚。而回溯就是回答这个问题的。
对于耗时这个根本问题,我们需要另外找到思路。
3、序列快速比对算法
3.1 简单方法
我们的目标不是一下子解决序列比对问题,而是先看一个简单一点的问题:如何在一个字符串中查找一个子串。比如字符串ABABAAB中子串ABA的位置是3。
计算机科学中,这个算法称为“字符串匹配”算法,其目的是在一个字符串中查找另一个字符串。前者称为主串,后者称为子串。这个算法中有一个“next值”概念。什么是next值?就是在匹配字符时,如果当前字符不匹配我们应该怎样重新定位子串。
是不是不好理解?没关系,别着急。我们看一个给定的子串:
AAAAB
比如假设主串是AAABAAAABBBCCA,则从左往右数,子串出现的第一个位置是5:
AAABAAAABBBCCA
通常,你会怎样在主串中寻找子串?方法不外乎是这样的。第一步,把子串的第一个字符和主串的第一个字符对齐:
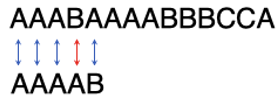
然后一个一个进行对比,对比到第4个字符发现不匹配。于是,把子串往右挪一位,把主串的指针从第4位往左挪回到第2位。再一个一个按顺序进行匹配:
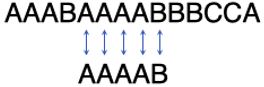
匹配到第3个字符时发现不匹配,再把子串往右挪一位。……,这个过程不断重复,直到最后找到匹配串:
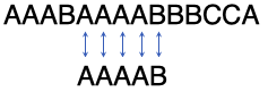
这个寻找子串的算法的时间复杂度是多少呢?假设主串的长度是m,子串的长度是n,则这个算法的复杂度是O(mn)。看起来好像也不是太吓人,但是别忘了,这只是寻找子串而已。对于字符串对比来说,寻找子串不过是最基础的操作之一。反映到字符串比对上,时间复杂度就是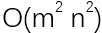 。
。
产生这个问题的根本原因是,每当字符不匹配时,我们不得不把主串和子串的指针挪回到开头。下面,我们简单介绍一种主串指针永不回头的匹配算法:基于next值的字符串匹配算法。
3.2、next值
回到上一节例子中主串和子串的第一步和第二步对比上,第一步:
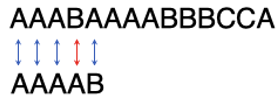
注意:这一步告诉了我们两个事实:1)主串的第4个字符肯定不是A;2)主串的头3个字符一定是AAA。记住这两个事实,我们下面会反复用到它们。
第二步,子串往右挪了一位,子串的第1个字符与主串的第2个字符对齐:
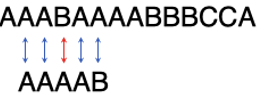
根据上述事实2),我们已经知道主串和子串的头三个字符是相等的,所以,第二步对比时,实际上没有必要再对比头两个字符了,它们注定相等,而是应该直接对比子串的第3个字符与主串的第4个字符:
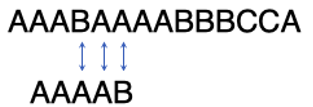
这样是不是就省掉了两次字符比较?可是,我们还能进一步节省字符比较。根据上述事实1),主串的第4个字符不可能是A,这意味这一次字符比较也不用进行了,它们注定不等。所以我们应该把子串再往右挪一位,让子串的第1个字符与主串的第3个字符对齐:
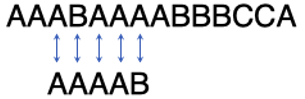
令人吃惊的是,此时仍然不必对比子串的第1个字符与主串的第3个字符,因为他们注定相等。为什么?因为上面第2)个事实告诉我们主串的头3个字符是AAA,这意味着子串的第1个字符与主串的第3个字符注定相等。所以我们只需对比子串的第2个字符与主串的第4个字符:
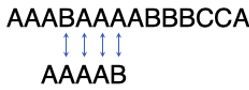
令人“崩溃”的是,这一步对比还是注定失败的。因为上述事实1)已经告诉了我们主串的第4个字符不是A!所以我们应该再次把子串往右挪一位,变成这样:

基于同样的分析,我们发现这一步对比仍然是注定失败的!所以再次把子串往右挪一位,变成:
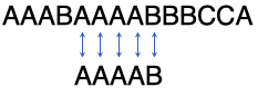
此时,我们才真正开始了字符对比。也就是说,对于子串AAAAB来说,当第4个字符不匹配时,应该把子串往右挪4位:

这个4就是子串中第4个字符的“next值”。子串中其他字符的next值见下表:

比如,利用上表,我们试图在主串ABABAAABBAAAABBB中找子串AAAAB:
第1步:
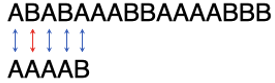
第2个字符不匹配,查表知道子串往右挪2位。
第2步:
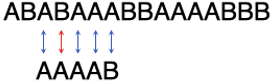
仍然是第2个字符不匹配,子串再往右挪2位。
第3步:
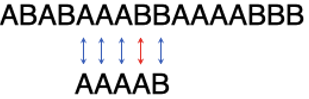
这次是第4个字符不匹配,查表得子串往右挪4位。
第4步:
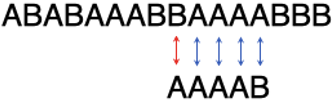
第1个字符不匹配,往右挪1位。
第5步:
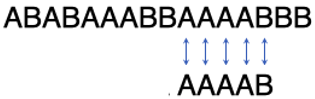
这一次所有字符都匹配了。于是我们找到了子串。我们总共进行了14次字符比较。而普通方法要进行22次字符比较才能找到子串。当子串很多很长时,这种差距就很明显了。
3.3、快速比对算法
我们的快速比对算法就是基于上述next值的。由于涉及到递归、回溯、问题分解、分枝定界等专业概念,比较复杂,所以这里就不再论述了。有兴趣的读者可以与我联系。
无相关信息