
五部门关于开展2024年新能源汽车下乡活动的通知
使用 DSP 加速 CORDIC 算法
来源:新能源汽车网
时间:2023-03-29 16:10:39
热度:311
使用 DSP 加速 CORDIC 算法数字信号处理器 (DSP) 为需要快速模拟到数字到模拟转换的应用处理数字,例如软件无线电和雷达。如果您没有使用 DSP,您可以使用 CORDI
数字信号处理器 (DSP) 为需要快速模拟到数字到模拟转换的应用处理数字,例如软件无线电和雷达。如果您没有使用 DSP,您可以使用 CORDIC 算法在您的 IC 上执行类似的计算。CORDIC 算法的优势在于它能够在不使用乘法器的情况下求解矢量旋转。
尽管 CORDIC 的属性有据可查,但您不会经常发现它在 DSP 上实现,因为 CORDIC 是 49 年前构思出来的,当时乘法器硬件的成本高得令人望而却步。(DSP 通常配备乘法器。)但是当您将两者混合时会发生什么情况?当在 DSP 处理器上实现 CORDIC 算法时,乘法器能否提高 CORDIC 的性能,还是可以闲置?
我们将通过提出一种将 CORDIC 算法映射到 DSP 硬件的新颖方法来积极回答这个问题。这种新方法使用 DSP 的 MAC(乘法/累加)单元并消除了条件,从而保留了机器流水线。
CORDIC 是 COordinate Rotation DIgital Computer 的首字母缩写词,是一类在平面中旋转矢量的移位相加算法。CORDIC 已成为内存和 CPU 受限嵌入式系统中的常用方法,因为它是计算每个科学计算器中的双曲函数和三角函数的简单而有效的方法。
大多数情况下,当没有可用的硬件乘法器时(例如在微控制器和 FPGA 中),会使用该算法,因为它所需的操作是加法、减法、位移位和查表。
CORDIC 由于其简单性和相对快速收敛的特性而被广泛使用。它有很多应用,包括计算三角函数和将笛卡尔坐标转换为极坐标(反之亦然)。
基本上,CORDIC 算法会选择特殊的旋转角度,这样它就可以通过简单的移位和加法来执行旋转操作,而不是一般情况下所需的乘法函数。因此,设计团队可以使用 CORDIC 算法而不是硬件乘法器,后者需要更多的门数并且构建成本更高。
在我们详细了解如何将 CORDIC 算法映射到 DSP 引擎之前,我们将简要回顾一下 CORDIC 算法,该算法根据笛卡尔坐标计算矢量的大小和角度。然后我们将描述该算法在 DSP 处理器上的实现,它仅使用加法和移位运算。
不过,首先让我们回顾一下实现 CORDIC 的传统方法。
令v为具有笛卡尔坐标 ( x, y ) 的向量。为了简化描述,我们只考虑单位圆的右半平面,换句话说,我们假设 1> x >0, 1> y。
目标是找到幅度
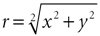
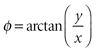
如果我们能以某种方式将向量v = ( x , y ) 旋转到v e = ( x e , y e ) 使得y e = 0,则大小r 将是x坐标x e ,角度 φ 将是旋转后的坐标角度。这种旋转实际上是通过多次连续旋转(称为子旋转)来实现的。对于每个子旋转,正确选择旋转角度,以便:
? 计算可以仅通过加法和移位运算来完成(避免使用乘法)。
? 子旋转集将向量v驱动 到x轴,换句话说,使坐标y 等于0;如果当前旋转是前一个旋转的一半,则可以保证这一点。
在数学上,CORDIC 算法可以描述如下:
初让:
x 0 = x
y 0 = y
φ 0 =0
个操作会将 v 0 = ( x 0 , y 0 ) 旋转 α 0 =45° 以获得 v 1 = ( x 1 , y 1 )。
x 1 = x 0 cos(α 0 ) – d 0 y 0 sin(α 0 ) (1.3)
y 1 = y 0 cos(α 0 ) + d 0 x 0 sin(α 0 ) (1.4)
φ 1 = φ 0 – d 0 α 0 (1.5)
其中d 0 是旋转方向:
d 0 =1 如果y 0 <0 (1.6)
d 0 =-1 如果y 0 ≥0 (1.7)
等式 1.3 和 1.4 与以下相同:
x 1 = cos(α 0 )[ x 0 – d 0 y 0 tan(α 0 )] (1.8)
y 1 = cos(α 0 )[ y 0 + d 0 x 0 tan(α 0 )] (1.9)
一般来说,第i次旋转是:
x i +1 = cos(α i )[ x i – d i y i tan(α i ) (1.10)
y i +1 = cos(α i )[ y i + d i x i tan(α i )] (1.11)
φ i +1 = φ i – d i α i (1.12)
其中d i 是旋转方向:
d i =1 如果y i <0(向上旋转) (1.13)
d i =-1 如果y i ≥0(向下旋转) (1.14)
因为我=0,1,…
如果选择 a i 使得 tan(a i )= 2 -i ,则方程 1.10 到 1.12 变为:
x i +1 = K i [ x i – d i y i 2 -i ] (1.15)
y i +1 = K i [ y i + d i x i 2 -i ] (1.16)
φ i +1 = φ i – d i α i (1.17)
在哪里:
K i = cos(arctan(2 -i )) (1.18)
α i = arctan(2 -i ) (1.19)
由于稍后可以去除常数K i 的影响 (参见公式 1.23),公式 1.15 到 1.17 中的 CORDIC 算法可以实现为:
xi +1 = xi – d i y i 2 -i ( 1.20 )
y i +1 = y i + d i x i 2 -i (1.21)
φ i +1 = φ i – d i α i (1.22)
其中d i 和 α i 在方程 1.13、1.14 和 1.19 中定义。
假设经过N 次旋转后,达到了所需的精度,则 可以通过以下方式近似找到 大小r和角度 φ:
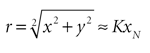
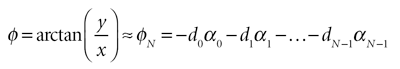
其中K = K N -1 ? …? K 0 = cos(arctan(2 -( N -1) ))?... ?cos(arctan(2 -0 )),可以地预先计算。
等式 1.20 到 1.24 中 CORDIC 的典型伪代码是:
如果 ( y < 0) (1.25)
x i +1 = x i – y i ' (1.26)
y i +1 = y i + x i ' (1.27)
φ i +1 = φ i – α i (1.28)
如果 ( y i ≥ 0) (1.29)
x i +1 = x i + y i ' (1.30)
y i +1 = y i – x i ' (1.31)
φ i +1 = φ i + α i (1.32)
在哪里:
x i '= x i 2 -i = x i >> i (1.33)
y i '= y i 2 -i = y i >> i (1.34)
我=0,1,…
符号“ z >> i ”表示z中的位 将向下移动i 位(本文档中的移位始终是算术移位,而不是逻辑移位)。
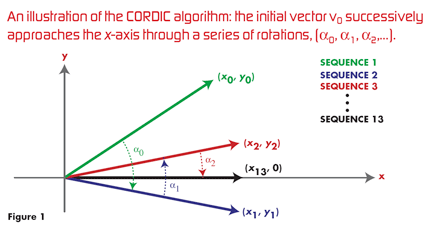
图 1 显示了 CORDIC 算法的图示。公式 1.25 到 1.32 中的伪代码很简单,只需要加法和移位运算。由于不需要乘法函数,硬件实现也很简单,因此CORDIC算法在ASIC(专用集成电路)和FPGA(现场可编程门阵列)中得到广泛应用。
查看全尺寸图像
现代架构的新 CORDIC 实现
人们普遍认为 DSP 处理器无法提高 CORDIC 算法的性能。乍一看,这似乎是合理的,因为在大多数实现中 CORDIC 的主要优势是它避免了乘法函数。但是,如果有一个乘法器,是否可以提高 CORDIC 算法的性能呢?我们建议重新制定 CORDIC,以利用 DSP 的硬件架构。
在 DSP 架构上实现 CORDIC 时还有另一个重要的考虑因素——即流水线。为了提高性能,现代处理器通常采用多达 10 个阶段的流水线。这种流水线设计允许处理器以时间片的方式执行任务。 只要代码不会用分支破坏指令流,流水线就是一种有效的方法。传统的 CORDIC 算法需要条件执行(参见方程 1.25 到 1.32 中的伪代码),这通常会破坏流水线并导致停顿。因此,CORDIC 算法的性能在现代流水线架构中可能很慢。
我们的新方法主要通过在 DSP 处理器中使用乘法单元来解决这个困难;它还消除了条件执行的需要。我们首先重新制定算法,使其更适合使用乘法器。
x i +1、y i +1和 φ i +1的迭代公式 (参见方程 1.25 至 1.32)可写为:
x i +1 = φ i ( x i – y i ')+(1- f i ) ( x i + y i ') (2.1)
y i +1 = fi ( y i + x i ')+(1- f i ) ( y i – x i ') ( 2.2)
f i +1 = φ i (φ i – a i )+(1- f i ) (φ i + α i ) (2.3)
在哪里:
f i =1 如果y i <0 (2.4)
f i =0 如果y i ≥0 (2.5)
x i '= x i 2 -i = x i >>i (2.6)
y i '= y i 2 -i = y i >>i (2.7)
公式 2.1 中的迭代可写为:
x i +1 = f i (– 2 y i ')+ ( x i + y i ')
= 2[- f i y i '+ x i /2+ y i '/2]
= 2[(- f i + 1 / 2) y i '+ x i /2] (2.8)
= 2[(- f i + 1 / 2)' y i + x i /2]
在哪里:
(- f i + 1 / 2)' = (- f i + 1 / 2)2 -i = (- f i + 1 / 2)>> i (2.9)
同样,方程 2.2 和 2.3 中的迭代可写为:
y i +1 = 2[-(- f i + 1 / 2)' x i + y i /2] (2.10)
φ i +1 = 2 i [(- f i + 1 / 2)α i +φ i /2] (2.11)
综合以上,我们有实现的算法:
x i +1 = 2[(- f i + 1 / 2)' y i + x i /2] (2.12)
y i +1 = 2[-(- f i + 1 / 2)' x i + y i /2] (2.13)
φ i +1 = 2 i [(- f i + 1 / 2)α i +φ i /2] (2.14)
在哪里:
f i =1 如果y i <0 (2.15)
f i =0 如果y i ≥ 0 (2.16)
(- f i + 1 / 2)' = (- f i + 1 / 2)2 – i = (- f i + 1 / 2)>>i (2.17)
公式 2.12 到 2.17 相对于公式 1.25 到 1.32 的优点如下:
1. 方程 2.12 到 2.17 的执行是无条件的;因此,它解决了管道破裂的困难,这是在执行方程式 1.25 到 1.32 时的情况。
2. 方程式 2.12 到 2.17 中的移位操作只会进行(以获得修改后的标志 (- f i + 1 / 2)' ),而在方程式 1.25 到 1.32 中,需要两次移位操作(以获得x i '和y i '),因此它节省了操作。
3. 标志已被选择为具有两个可能的值,1 / 2 或 –1 / 2。公式 1.15 小数格式中的这些值分别以十六进制表示法表示为 0x4000 和 0xC000。由于特定值的选择,标志常量在向下移动时不会丢失精度。
4. 新的CORDIC公式在迭代过程中不会下移x i 和y i坐标值。 因此,原始 ( x , y ) 坐标值的精度不会丢失。
5. 标志 (- f i +1 / 2)' 与x i 或y i 坐标值的乘积存储在 40 位累加器中。参见公式 2.8 和 2.10。
6. 作为改进 3、4 和 5 的结果,新的 CORDIC 公式实现了约 0.5 位的更高精度。
公式 2.12 到 2.17 中的公式特别适合在流水线 DSP 架构上实现。当在 Analog Devices 的 Blackfin BF533 DSP 处理器上实现时,每次迭代需要四个周期,而公式 1.25 到 1.32 中的传统实现每次迭代需要七个周期。例如,在软件无线电应用中,我们需要为 240 kHz 的两个信道实现 CORDIC 算法。迭代次数(子旋转)为 13。我们的新方法将消耗 2×240,000x13x4 = 25 mips(每秒百万条指令),而 2×240,000x13x7 = 44 mips。
这表示在 mips 方面节省了 43%。此外,对于相同的迭代次数,方程式 2.12 到 2.17 中新方法的结果平均比方程式 1.25 到 1.32 中的传统方法的精度高 0.5 位。
CORDIC 的 C 和汇编代码
在本节中,我们提供三个代码示例:
? 清单 1: 实现原始 CORDIC 的 C 代码。
? 清单 2:实现重新编写的 CORDIC 的 Blackfin 汇编代码。
? 清单 3: 实现原始 CORDIC 的 Blackfin 汇编代码。
可以使用 ADI 的 VisualDSP++ 工具编译和执行清单 1中的代码和清单 2 中的完整代码。请注意,清单 2中的代码 是一个摘录——完整的代码代码假定 | x |, | y |<1 格式为 1.15;换句话说,x , y在[0x8000, 0x7fff] 范围内。输出相位为1.31格式的32位;换句话说,-p 由0x80000000 表示 ,p 由0x7fffffff 表示。汇编代码可能有一些特殊要求,可以在注释中看到。



清单 3中的代码 只是展示原始 CORDIC 如何在 ADI 汇编上实现的一部分。在清单 3中,我们仅显示了迭代的代码(总共七行代码,花费了七个周期)。ITER_NUM=i 是一个变量i =0,…,14 是迭代次数。它应该在一个寄存器中,可以从内存中加载。为了清楚起见,我们将其保留原样。寄存器 r2 = φ i +1 , i =0,1,…,14 初始时 r2=φ 0 =0(见 1.32)。除了以下实现的缓慢性能外,由于行r1 = r0>>> ITER_NUM (v) ,它的精度较低,它移动了x i y i 向下坐标,失去精度。数字信号处理器 (DSP) 为需要快速模拟到数字到模拟转换的应用处理数字,例如软件无线电和雷达。如果您没有使用 DSP,您可以使用 CORDIC 算法在您的 IC 上执行类似的计算。CORDIC 算法的优势在于它能够在不使用乘法器的情况下求解矢量旋转。
尽管 CORDIC 的属性有据可查,但您不会经常发现它在 DSP 上实现,因为 CORDIC 是 49 年前构思出来的,当时乘法器硬件的成本高得令人望而却步。(DSP 通常配备乘法器。)但是当您将两者混合时会发生什么情况?当在 DSP 处理器上实现 CORDIC 算法时,乘法器能否提高 CORDIC 的性能,还是可以闲置?
我们将通过提出一种将 CORDIC 算法映射到 DSP 硬件的新颖方法来积极回答这个问题。这种新方法使用 DSP 的 MAC(乘法/累加)单元并消除了条件,从而保留了机器流水线。
CORDIC 是 COordinate Rotation DIgital Computer 的首字母缩写词,是一类在平面中旋转矢量的移位相加算法。CORDIC 已成为内存和 CPU 受限嵌入式系统中的常用方法,因为它是计算每个科学计算器中的双曲函数和三角函数的简单而有效的方法。
大多数情况下,当没有可用的硬件乘法器时(例如在微控制器和 FPGA 中),会使用该算法,因为它所需的操作是加法、减法、位移位和查表。
CORDIC 由于其简单性和相对快速收敛的特性而被广泛使用。它有很多应用,包括计算三角函数和将笛卡尔坐标转换为极坐标(反之亦然)。
基本上,CORDIC 算法会选择特殊的旋转角度,这样它就可以通过简单的移位和加法来执行旋转操作,而不是一般情况下所需的乘法函数。因此,设计团队可以使用 CORDIC 算法而不是硬件乘法器,后者需要更多的门数并且构建成本更高。
在我们详细了解如何将 CORDIC 算法映射到 DSP 引擎之前,我们将简要回顾一下 CORDIC 算法,该算法根据笛卡尔坐标计算矢量的大小和角度。然后我们将描述该算法在 DSP 处理器上的实现,它仅使用加法和移位运算。
不过,首先让我们回顾一下实现 CORDIC 的传统方法。
令v为具有笛卡尔坐标 ( x, y ) 的向量。为了简化描述,我们只考虑单位圆的右半平面,换句话说,我们假设 1> x >0, 1> y。
目标是找到幅度
如果我们能以某种方式将向量v = ( x , y ) 旋转到v e = ( x e , y e ) 使得y e = 0,则大小r 将是x坐标x e ,角度 φ 将是旋转后的坐标角度。这种旋转实际上是通过多次连续旋转(称为子旋转)来实现的。对于每个子旋转,正确选择旋转角度,以便:
? 计算可以仅通过加法和移位运算来完成(避免使用乘法)。
? 子旋转集将向量v驱动 到x轴,换句话说,使坐标y 等于0;如果当前旋转是前一个旋转的一半,则可以保证这一点。
在数学上,CORDIC 算法可以描述如下:
初让:
x 0 = x
y 0 = y
φ 0 =0
个操作会将 v 0 = ( x 0 , y 0 ) 旋转 α 0 =45° 以获得 v 1 = ( x 1 , y 1 )。
x 1 = x 0 cos(α 0 ) – d 0 y 0 sin(α 0 ) (1.3)
y 1 = y 0 cos(α 0 ) + d 0 x 0 sin(α 0 ) (1.4)
φ 1 = φ 0 – d 0 α 0 (1.5)
其中d 0 是旋转方向:
d 0 =1 如果y 0 <0 (1.6)
d 0 =-1 如果y 0 ≥0 (1.7)
等式 1.3 和 1.4 与以下相同:
x 1 = cos(α 0 )[ x 0 – d 0 y 0 tan(α 0 )] (1.8)
y 1 = cos(α 0 )[ y 0 + d 0 x 0 tan(α 0 )] (1.9)
一般来说,第i次旋转是:
x i +1 = cos(α i )[ x i – d i y i tan(α i ) (1.10)
y i +1 = cos(α i )[ y i + d i x i tan(α i )] (1.11)
φ i +1 = φ i – d i α i (1.12)
其中d i 是旋转方向:
d i =1 如果y i <0(向上旋转) (1.13)
d i =-1 如果y i ≥0(向下旋转) (1.14)
因为我=0,1,…
如果选择 a i 使得 tan(a i )= 2 -i ,则方程 1.10 到 1.12 变为:
x i +1 = K i [ x i – d i y i 2 -i ] (1.15)
y i +1 = K i [ y i + d i x i 2 -i ] (1.16)
φ i +1 = φ i – d i α i (1.17)
在哪里:
K i = cos(arctan(2 -i )) (1.18)
α i = arctan(2 -i ) (1.19)
由于稍后可以去除常数K i 的影响 (参见公式 1.23),公式 1.15 到 1.17 中的 CORDIC 算法可以实现为:
xi +1 = xi – d i y i 2 -i ( 1.20 )
y i +1 = y i + d i x i 2 -i (1.21)
φ i +1 = φ i – d i α i (1.22)
其中d i 和 α i 在方程 1.13、1.14 和 1.19 中定义。
假设经过N 次旋转后,达到了所需的精度,则 可以通过以下方式近似找到 大小r和角度 φ:
其中K = K N -1 ? …? K 0 = cos(arctan(2 -( N -1) ))?... ?cos(arctan(2 -0 )),可以地预先计算。
等式 1.20 到 1.24 中 CORDIC 的典型伪代码是:
如果 ( y < 0) (1.25)
x i +1 = x i – y i ' (1.26)
y i +1 = y i + x i ' (1.27)
φ i +1 = φ i – α i (1.28)
如果 ( y i ≥ 0) (1.29)
x i +1 = x i + y i ' (1.30)
y i +1 = y i – x i ' (1.31)
φ i +1 = φ i + α i (1.32)
在哪里:
x i '= x i 2 -i = x i >> i (1.33)
y i '= y i 2 -i = y i >> i (1.34)
我=0,1,…
符号“ z >> i ”表示z中的位 将向下移动i 位(本文档中的移位始终是算术移位,而不是逻辑移位)。
图 1 显示了 CORDIC 算法的图示。公式 1.25 到 1.32 中的伪代码很简单,只需要加法和移位运算。由于不需要乘法函数,硬件实现也很简单,因此CORDIC算法在ASIC(专用集成电路)和FPGA(现场可编程门阵列)中得到广泛应用。
现代架构的新 CORDIC 实现
人们普遍认为 DSP 处理器无法提高 CORDIC 算法的性能。乍一看,这似乎是合理的,因为在大多数实现中 CORDIC 的主要优势是它避免了乘法函数。但是,如果有一个乘法器,是否可以提高 CORDIC 算法的性能呢?我们建议重新制定 CORDIC,以利用 DSP 的硬件架构。
在 DSP 架构上实现 CORDIC 时还有另一个重要的考虑因素——即流水线。为了提高性能,现代处理器通常采用多达 10 个阶段的流水线。这种流水线设计允许处理器以时间片的方式执行任务。 只要代码不会用分支破坏指令流,流水线就是一种有效的方法。传统的 CORDIC 算法需要条件执行(参见方程 1.25 到 1.32 中的伪代码),这通常会破坏流水线并导致停顿。因此,CORDIC 算法的性能在现代流水线架构中可能很慢。
我们的新方法主要通过在 DSP 处理器中使用乘法单元来解决这个困难;它还消除了条件执行的需要。我们首先重新制定算法,使其更适合使用乘法器。
x i +1、y i +1和 φ i +1的迭代公式 (参见方程 1.25 至 1.32)可写为:
x i +1 = φ i ( x i – y i ')+(1- f i ) ( x i + y i ') (2.1)
y i +1 = fi ( y i + x i ')+(1- f i ) ( y i – x i ') ( 2.2)
f i +1 = φ i (φ i – a i )+(1- f i ) (φ i + α i ) (2.3)
在哪里:
f i =1 如果y i <0 (2.4)
f i =0 如果y i ≥0 (2.5)
x i '= x i 2 -i = x i >>i (2.6)
y i '= y i 2 -i = y i >>i (2.7)
公式 2.1 中的迭代可写为:
x i +1 = f i (– 2 y i ')+ ( x i + y i ')
= 2[- f i y i '+ x i /2+ y i '/2]
= 2[(- f i + 1 / 2) y i '+ x i /2] (2.8)
= 2[(- f i + 1 / 2)' y i + x i /2]
在哪里:
(- f i + 1 / 2)' = (- f i + 1 / 2)2 -i = (- f i + 1 / 2)>> i (2.9)
同样,方程 2.2 和 2.3 中的迭代可写为:
y i +1 = 2[-(- f i + 1 / 2)' x i + y i /2] (2.10)
φ i +1 = 2 i [(- f i + 1 / 2)α i +φ i /2] (2.11)
综合以上,我们有实现的算法:
x i +1 = 2[(- f i + 1 / 2)' y i + x i /2] (2.12)
y i +1 = 2[-(- f i + 1 / 2)' x i + y i /2] (2.13)
φ i +1 = 2 i [(- f i + 1 / 2)α i +φ i /2] (2.14)
在哪里:
f i =1 如果y i <0 (2.15)
f i =0 如果y i ≥ 0 (2.16)
(- f i + 1 / 2)' = (- f i + 1 / 2)2 – i = (- f i + 1 / 2)>>i (2.17)
公式 2.12 到 2.17 相对于公式 1.25 到 1.32 的优点如下:
1. 方程 2.12 到 2.17 的执行是无条件的;因此,它解决了管道破裂的困难,这是在执行方程式 1.25 到 1.32 时的情况。
2. 方程式 2.12 到 2.17 中的移位操作只会进行(以获得修改后的标志 (- f i + 1 / 2)' ),而在方程式 1.25 到 1.32 中,需要两次移位操作(以获得x i '和y i '),因此它节省了操作。
3. 标志已被选择为具有两个可能的值,1 / 2 或 –1 / 2。公式 1.15 小数格式中的这些值分别以十六进制表示法表示为 0x4000 和 0xC000。由于特定值的选择,标志常量在向下移动时不会丢失精度。
4. 新的CORDIC公式在迭代过程中不会下移x i 和y i坐标值。 因此,原始 ( x , y ) 坐标值的精度不会丢失。
5. 标志 (- f i +1 / 2)' 与x i 或y i 坐标值的乘积存储在 40 位累加器中。参见公式 2.8 和 2.10。
6. 作为改进 3、4 和 5 的结果,新的 CORDIC 公式实现了约 0.5 位的更高精度。
公式 2.12 到 2.17 中的公式特别适合在流水线 DSP 架构上实现。当在 Analog Devices 的 Blackfin BF533 DSP 处理器上实现时,每次迭代需要四个周期,而公式 1.25 到 1.32 中的传统实现每次迭代需要七个周期。例如,在软件无线电应用中,我们需要为 240 kHz 的两个信道实现 CORDIC 算法。迭代次数(子旋转)为 13。我们的新方法将消耗 2×240,000x13x4 = 25 mips(每秒百万条指令),而 2×240,000x13x7 = 44 mips。
这表示在 mips 方面节省了 43%。此外,对于相同的迭代次数,方程式 2.12 到 2.17 中新方法的结果平均比方程式 1.25 到 1.32 中的传统方法的精度高 0.5 位。
CORDIC 的 C 和汇编代码
在本节中,我们提供三个代码示例:
? 清单 1: 实现原始 CORDIC 的 C 代码。
? 清单 2:实现重新编写的 CORDIC 的 Blackfin 汇编代码。
? 清单 3: 实现原始 CORDIC 的 Blackfin 汇编代码。
可以使用 ADI 的 VisualDSP++ 工具编译和执行清单 1中的代码和清单 2 中的完整代码。请注意,清单 2中的代码 是一个摘录——完整的代码可以从www.embedded.com/code/2008code.htm 获得。代码假定 | x |, | y |<1 格式为 1.15;换句话说,x , y在[0x8000, 0x7fff] 范围内。输出相位为1.31格式的32位;换句话说,-p 由0x80000000 表示 ,p 由0x7fffffff 表示。汇编代码可能有一些特殊要求,可以在注释中看到。
清单 3中的代码 只是展示原始 CORDIC 如何在 ADI 汇编上实现的一部分。在清单 3中,我们仅显示了迭代的代码(总共七行代码,花费了七个周期)。ITER_NUM=i 是一个变量i =0,…,14 是迭代次数。它应该在一个寄存器中,可以从内存中加载。为了清楚起见,我们将其保留原样。寄存器 r2 = φ i +1 , i =0,1,…,14 初始时 r2=φ 0 =0(见 1.32)。除了以下实现的缓慢性能外,由于行r1 = r0>>> ITER_NUM (v) ,它的精度较低,它移动了x i y i 向下坐标,失去精度。


-
如何使用 FPGA 测试 PLL 频带校准算法2023-03-28
-
DSP 技巧:频率解调算法2023-03-20
-
FPGA数字信号处理之CORDIC算法2023-03-08
-
集度概念车落地!经典AI专利解读:下坡路能量回收算法精准降能耗2022-11-08
-
威马被爆工资7折发放/理想汽车AI算法负责人将离职2022-10-25
-
解锁代码重复使用!本田被曝安全漏洞,黑客可远程解锁甚至启动汽车2022-07-14
-
游戏规则悄然发生变化,汽车公司深陷“代码”牢笼2022-06-29
-
开源AEB代码,理想汽车意在何为?2022-06-24
-
疲劳驾驶检测技术哪家强?奇瑞专利解读:眼、嘴特征提取算法判定疲劳值2022-03-07
-
激光雷达VS视觉算法,两派路线之争,求同存异的差异化角逐2022-02-23
-
百度Apollo7.0 规划算法框架解析2022-02-07
-
宁德时代与深势科技达成合作 共建联合实验室推动先进算法在新能源领域的应用2021-11-30
-
美国研究者研发量子力学算法 欲模拟驾驶情境攻克决策难题2021-08-20
-
我国新能源车人才缺口巨大,新一代“算法人”炙手可热2021-07-27
-
芯原股份领投一清创新,模块化自动驾驶算法融合半导体IP业务2021-07-23